SSR-CoT Dataset
A million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations
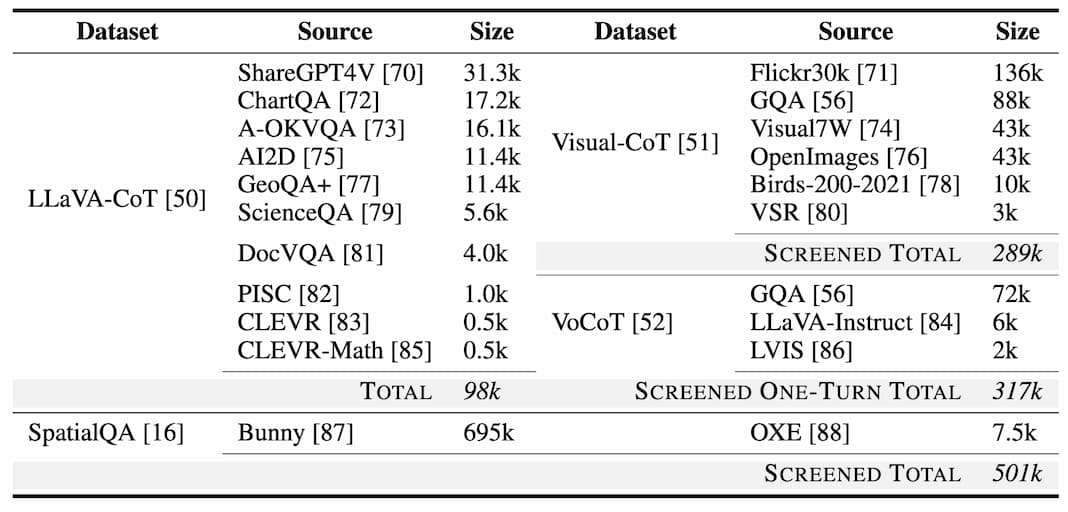
We curate a new dataset SSR-CoT from existing VQA datasets, resulting in over a total of 1 million image-depth-question-rationale-answer pairs. There are four dataset sources we integrated: LLaVA-CoT, Visual-CoT, VoCoT, and SpatialQA.
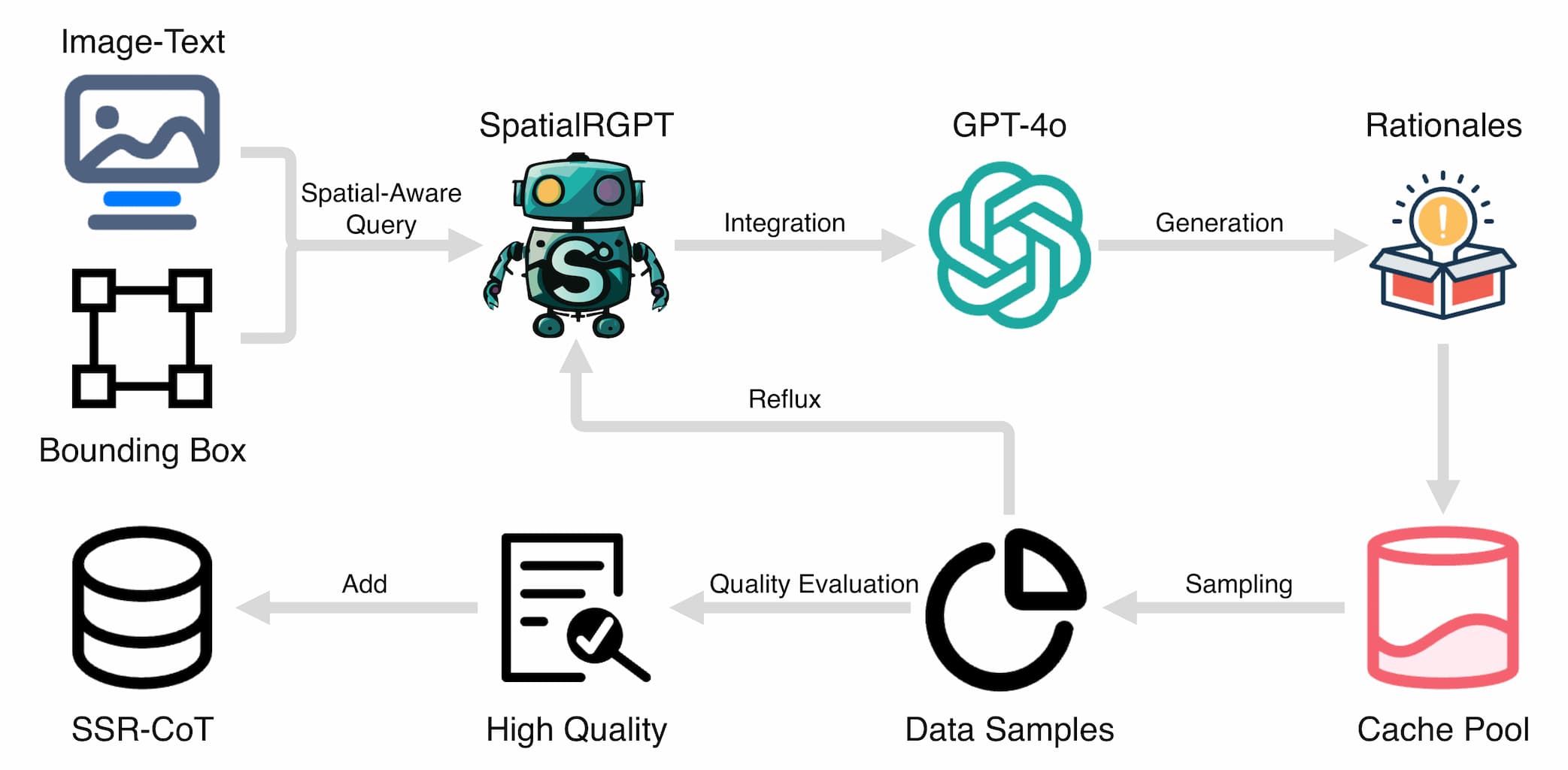
To generate visual-language reasoning data enriched with spatial information, we follow a multi-step process.
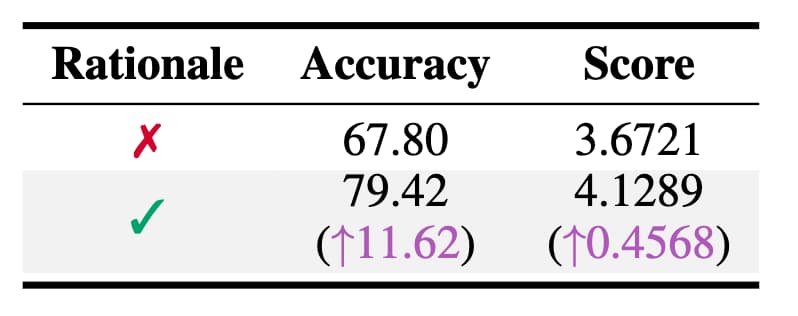
To evaluate the quality of SSR-CoT, we conducted an assessment based on the performance of the Qwen2.5-VL-7B-Instruct on the VQA task. This evaluation was carried out on a randomly selected subset comprising approximately 1% of the full dataset, corresponding roughly to 10k samples. Performance metrics include accuracy as well as a quantitative score ranging from 0 to 5, both are produced using the LLM-Assistant powered by the Qwen2.5-14B-Instruct-1M.

Each data instance within SSR-CoT comprises the original image, an associated question-answer pair, the corresponding estimated depth information, and a rationale. The rationale incorporates fundamental reasoning steps used in question-answering tasks and provides detailed spatial reasoning to support accurate answer generation.